There’s lot of information on NUMA implementation from processors manufacturers and software vendors, which can sometimes become a challenge and you end up re-visiting multiple blogs and VMware PDF files — This blog is a consolidation (one reference point) to understand NUMA, vNUMA, “why it is important in the world of hypervisors?”, changes in vNUMA from vSphere v6.5 onwards, configuration overrides, Rule of thumb, recommendations on “Cores per Socket” configuration for vSphere v6.7 and v7.0.
What is NUMA ?
Let’s begin with “UMA” (Uniform Memory Architecture) architecture, which is described as all processors accessing memory through a shared bus (or another type of interconnect). NUMA (Non-Uniform Memory Access), is also a shared memory architecture but it describes the placement of main memory modules with respect to processors in a multiprocessor system i.e. each processor has its own local memory module that it can access directly with a distinctive performance advantage. At the same time, it can also access any memory module belonging to another processor using a shared bus.
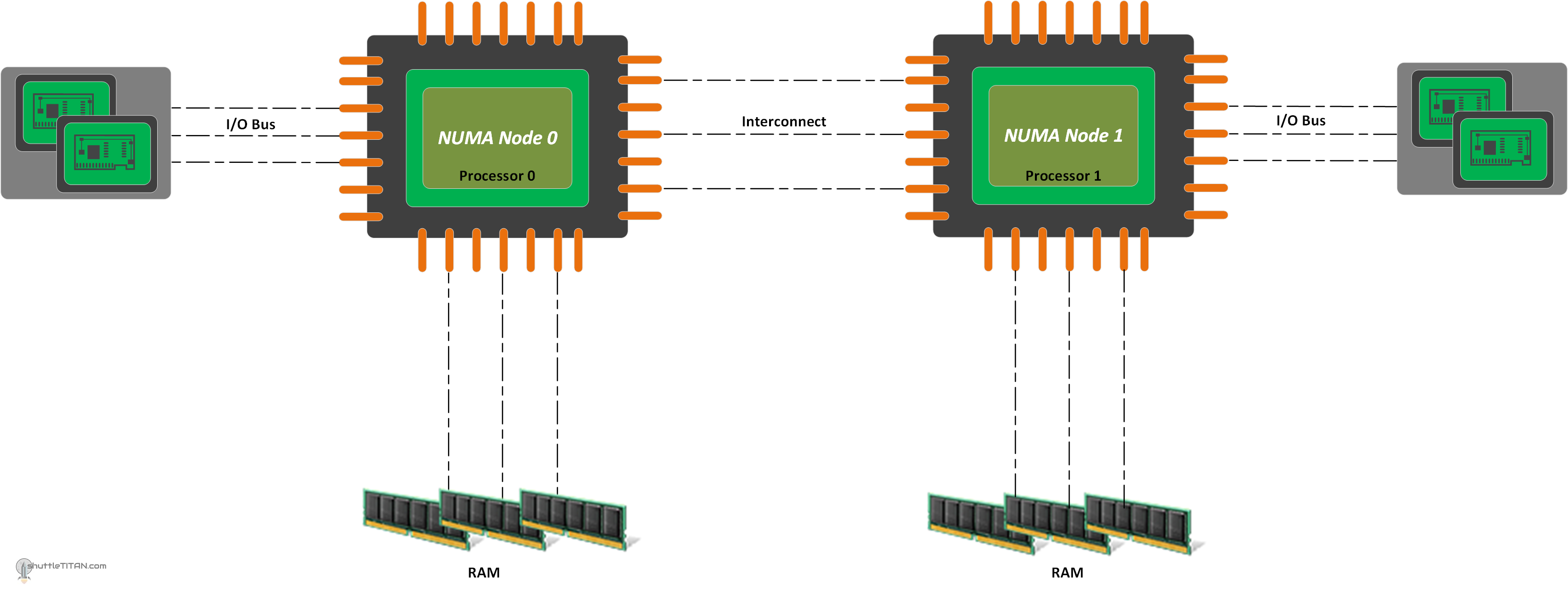
Why is it important in the world of hypervisor’s?
In general, NUMA awareness is important whenever you are using a server that supports two or more physical processor sockets. For example, in a two-socket server (image above), processor 1 accessing the memory that is directly attached to processor 0 will be slower than processor 1 accessing the memory directly attached to it because processor 1 will have to cross an inter-processor bus. This access is “non-uniform” in the sense that processor 0 will access this memory faster than processor 1 does, due to the longer access distance.
A NUMA Node is referred to as a processor with direct attached memory. Under some (but not all) conditions, accessing memory or devices across NUMA boundaries will result in decreased performance.
This becomes evident for VMs to utilize directly attached memory to the processor its running on, else (in some cases) the VM running will take some form of performance hit.
NUMA on vSphere:
For ESXi, to determine a system behaves like NUMA is done by a setting in BIOS, called “node interleaving” (also known as interleaved memory). If the node interleaving is disabled, ESXi detects the system as NUMA and applies NUMA optimizations. If node interleaving is enabled, ESXi does not detect the system as NUMA. For more information, refer to your server’s documentation.
With vSphere 4.1 the ability to present an option to define vCPU Cores and Socket was first introduced. In vSphere 5, the configuration determined the vNUMA topology exposed to the Operating System.
The intelligent, adaptive NUMA scheduling and memory placement policies in ESXi can manage all virtual machines transparently, so that administrators don’t need to deal with the complexity of balancing virtual machines between nodes by hand.
By default, ESXi NUMA scheduling and related optimizations are enabled only on systems with a total of at least four CPU cores and with at least two CPU cores per NUMA node.
NUMA Override / Advance configuration:
- Manual controls are available to override this default behavior, however, and advanced administrators might prefer to manually set NUMA placement by adding the setting in the VM configuration file:
numa.nodeAffinity = 0,1
The value 0 and 1 constrains the VM resourcing scheduling to NUMA nodes 0 and 1.
- On hyper-threaded systems, virtual machines with a number of vCPUs greater than the number of cores in a NUMA node but lower than the number of logical processors in each physical NUMA node might benefit from using logical processors with local memory instead of full cores with remote memory. This behavior can be configured for a specific virtual machine or for all VMs running on the physical host by using the following settings:
– For specific VM ,add the following configuration in the .vmx file (of from the GUI using advance configuration)
numa.vcpu.preferHT=True
– For all VMs to use hyper-threading with NUMA, add the following configuration on the ESXi Host Advance settings:
numa.PreferHT=1
These are advanced settings designed to help workloads that are cache-intensive, but not CPU intensive.
vNUMA on vSphere
Virtual NUMA (vNUMA) exposes NUMA topology to the guest operating system, allowing NUMA-aware guest operating systems and applications to make the most efficient use of the underlying hardware’s NUMA architecture.
Virtual NUMA, requires virtual hardware version 8 or later, can in some cases provide significant performance benefits for wide virtual machines (that is, virtual machines with more vCPUs than the number of cores in each physical NUMA node), though the benefits depend heavily on the level of NUMA optimization in the guest operating system and applications.
OS and applications potentially encounter remote memory access latencies while expecting local memory latencies after optimizing thread placements. It’s recommended to configure the VM’s “Cores per Socket” config to align with the physical boundaries of the CPU package.
vNUMA with vSphere 6.5 and later:
From vSphere v6.5 and later, vNUMA handling improved – which automatically determines the proper vNUMA topology to present to the guest OS based on the underlying ESXi host. The “Cores per Socket” no longer influences vNUMA or the configuration of the vNUMA topology. The configuration “Cores per Socket” now only affects the presentation of the virtual processors to the guest OS, something potentially relevant for software licensing.
For example: prior to vSphere v6.5, on a dual-socket physical ESXi host with 16 core per socket (for a total of 32 physical cores) – if you create a four-vSocket virtual machine and set cores per socket to four (for a total of 16 vCPUs), vNUMA would have created four vNUMA nodes based on the corespersocket setting. In vSphere 6.5 and later, the guest OS will still see four sockets and four cores per socket, but vNUMA will now create just one 16-core vNUMA node for the entire virtual machine because that virtual machine can be placed in a single physical NUMA node – but wait, see the “The Caveat” later in the blog below.
This new decoupling of the corespersocket setting from vNUMA allows vSphere to automatically determine the best vNUMA topology, unless the VMs Advance Virtual NUMA Attributes.
Considerations:
- “CPU Hot Add” or “CPU Hot Plug” is a feature that allows the addition of vCPUs to a running virtual machine. Enabling this feature, disables vNUMA for the respective virtual machine, resulting in the guest OS seeing a single vNUMA node. This in turn could result in the guest OS making sub-optimal scheduling decisions, leading to reduced performance for applications running in large virtual machines. Therefore, consider the use of this option only if you will need it.
- By default, vNUMA is enabled only for virtual machines with more than eight vCPUs. This feature can be enabled for smaller virtual machines, however, while still allowing ESXi to automatically manage the vNUMA topology. This can be useful for wide virtual machines (that is, virtual machines with more vCPUs than the number of cores in each physical NUMA node) with eight or fewer vCPUs.
vNUMA Overrides/Advance Configuration:
- To enable vNUMA for virtual machines with eight or fewer vCPUs the following configuration value can be added in the .vmx file:
numa.vcpu.min=X
Note: X is the number of vCPUs in the virtual machine.
- To revert the automatic vNUMA topology to old behaviour and directly control vNUMA node sizing being tied to cpuid.coresPerSocket, the following configuration value can be added in the .vmx file:
numa.vcpu.followcorespersocket=1
The Caveat:
The automatic vNUMA node determination from vSphere v6.5 and later is great optimization for handling VM’s CPU and Memory to align with pNUMA however the number virtual sockets does not consider the “cache address space” i.e. L3 cache. Therefore, it is recommended to take caution while configuring “Cores per Socket” and it should be aligned considering the boundaries of the physical CPUs for optimal performance. For more information and deep dive, see Frank Denneman’s blog here.
Rules of Thumb (by “Mark Achtemichuk”), still applies to Sphere v6.7 and 7.0:
- While there are many advanced vNUMA settings, only in rare cases do they need to be changed from defaults.
- Always configure the virtual machine vCPU count to be reflected as Cores per Socket, until you exceed the physical core count of a single physical NUMA node OR until you exceed the total memory available on a single physical NUMA node.
- When you need to configure more vCPUs than there are physical cores in the NUMA node, OR if you assign more memory than a NUMA node contains, evenly divide the vCPU count across the minimum number of NUMA nodes.
- Don’t assign an odd number of vCPUs when the size of your virtual machine, measured by vCPU count or configured memory, exceeds a physical NUMA node.
- Don’t enable vCPU Hot Add unless you’re okay with vNUMA being disabled.
- Don’t create a VM larger than the total number of physical cores of your host.
The table below outlines how a virtual machine should be configured, if the VM’s memory configuration is less than or equal to the pNUMA node memory, to ensure an optimal vNUMA topology and performance regardless of vSphere version:
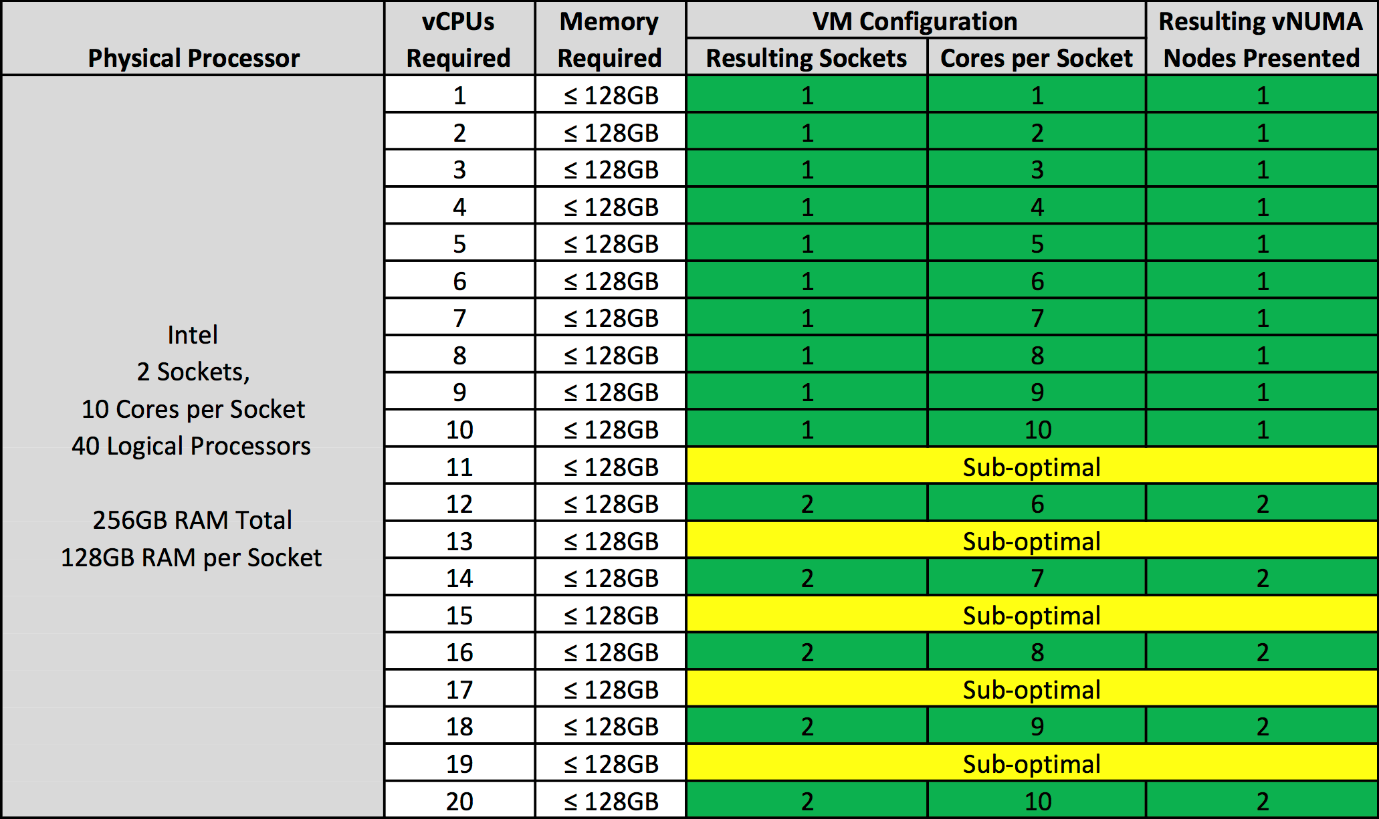
Image/Table credit – VMware Blog
The table below outlines how a virtual machine should be configured, if the VM’s memory configuration is more then the pNUMA node memory, to ensure an optimal vNUMA topology and performance regardless of vSphere version:
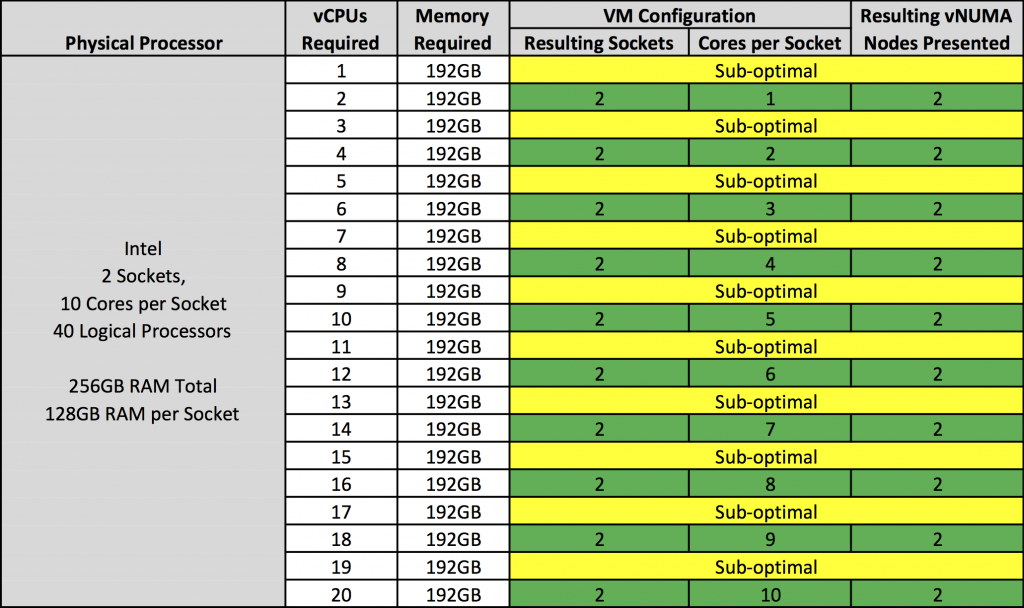
Image/Table credit – VMware Blog
The sources of information, that I used to consolidate this blog:
————————————————————————————————————–
- https://software.intel.com/en-us/articles/optimizing-applications-for-numa
- https://software.intel.com/en-us/articles/use-intel-quickassist-technology-efficiently-with-numa-awareness
- https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/performance/vsphere-esxi-vcenter-server-67-performance-best-practices.pdf
- https://blogs.vmware.com/performance/2017/03/virtual-machine-vcpu-and-vnuma-rightsizing-rules-of-thumb.html
- https://docs.vmware.com/en/VMware-vSphere/6.7/vsphere-esxi-vcenter-server-67-resource-management-guide.pdf
- https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/performance/vsphere-esxi-vcenter-server-67-performance-best-practices.pdf
- https://frankdenneman.nl/2016/12/12/decoupling-cores-per-socket-virtual-numa-topology-vsphere-6-5/
- https://frankdenneman.nl/2010/12/28/node-interleaving-enable-or-disable/
AWESOME INFORMATION! Thank you so much for taking the time to consolidate all of this and present it in a very concise and easily discernable way. Great job.
Thanks for explaining NUMA/vNUMA in a way that is easy to understand.